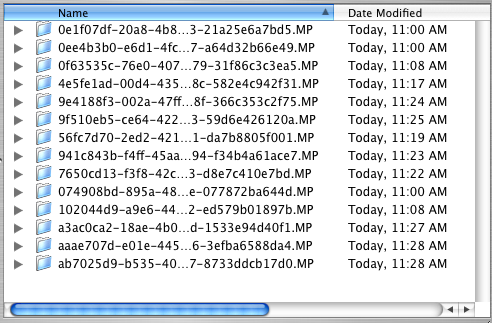
Today I was briefly confused by the Mac Finder. It sorted a collection of files in a surprising order.
screenshot
It appears that if Finder sees a number in a filename, it tokenizes that number and sorts it numerically before progressing to sorting subsequent alpha characters. This leads to unexpected sorting of files named hexadecimally.
Purely out of curiousity, I whipped up an implementation of this sort algorithm. Is there an easier way to do this?
use Test::More tests => 1;
my @items = ;
for (@items) { s/ //g; } # remove use.perl.org spaces
is_deeply([sort macsort @items], \@items);
sub macsort {
my @a = split /(\d+)/, $a;
my @b = split /(\d+)/, $b;
while (@a && @b) {
my $a_token = shift @a;
my $b_token = shift @b;
my $cmp = $a_token =~ /\A\d+\z/ && $b_token =~ /\A\d+\z/
? $a_token <=> $b_token
: $a_token cmp $b_token;
return $cmp if $cmp;
}
return 1 if @a;
return -1 if @b;
return 0;
}
__DATA__
0e1f07df-20a8-4b82-a3b3-21a25e6a7bd5.MP
0ee4b3b0-e6d1-4fca-8d27-a64d32b66e49.MP
0f63535c-76e0-407a-9a79-31f86c3c3ea5.MP
4e5fe1ad-00d4-435c-b18c-582e4c942f31.MP
9e4188f3-002a-47ff-bf8f-366c353c2f75.MP
9f510eb5-ce64-4222-aba3-59d6e426120a.MP
56fc7d70-2ed2-421f-adb1-da7b8805f001.MP
941c843b-f4ff-45aa-bb94-f34b4a61ace7.MP
7650cd13-f3f8-42c2-9f33-d8e7c410e7bd.MP
074908bd-895a-48d5-83ae-077872ba644d.MP
102044d9-a9e6-4454-9182-ed579b01897b.MP
a3ac0ca2-18ae-4b02-badd-1533e94d40f1.MP
aaae707d-e01e-4454-a856-3efba6588da4.MP
ab7025d9-b535-40bb-8807-8733ddcb17d0.MP
b357c383-7469-48b1-9c17-0fd2973b7896.MP
e3da5d7d-911d-4ba5-9654-9d579e5e1846.MP
was IMHO an inspired one, so I cannot improve on that idea. Do note that the numeric string sections will always be at the list items with odd index (1, 3, 5,split/(\d+)/
split array:BTW you forgot tomy %orcache;
sub macsort {
my $A = $orcache{$a} ||= [ split/(\d+)/, $a ];
my $B = $orcache{$b} ||= [ split/(\d+)/, $b ];
my $cmp;
for(my $i = 0; $i < @$A && $i < @$B; $i++) {
$cmp = $i & 1
? $A->[$i] <=> $B->[$i]
: $A->[$i] cmp $B->[$i]
and return $cmp;
}
return @$A cmp @$B;
}
chomp the data, which may produce unexpected results when sorting the items, as there's a newline appended to every last array item.
Re:I think they call this a "natural sort"
ChrisDolan on 2006-12-13T01:37:21
Nice implementation. I think the last line is better written as:but since one of them must be zero, the results are equivalent.return @$A <=> @$B;
Isi & 1preferable toi % 1? I consider the latter to be slightly more intuitive.
BTW you forgot to chomp the data
Yeah, I skipped that just for simplicity of the example It doesn't affect the test case.Re:I think they call this a "natural sort"
bart on 2006-12-13T17:57:31
I think the last line is better written as:Uh, of course, that's what I planned to write. I had been messing with the implementation showing debugging information during the comparison, and this must be a leftover. That's my story and I'm sticking to it.return @$A <=> @$B;;-) Is i & 1 preferable to i % 1? I consider the latter to be slightly more intuitive.At least it gives the correct results.:-) Surely you ment to type $i % 2.A recent thread on Perlmonks by diotalevi shows that nowadays, these instructions take the same time. It used to make a difference, in my favour, 20 years ago — before the numerical coprocessors, that all CPUs have embedded, nowadays.
But it did have strange effects when I added a test case, where not all strings split into an equal number of parts, and the part that some do have in common is the same. Or so I thought.BTW you forgot to chomp the dataI skipped that just for simplicity of the example It doesn't affect the test case.Re:I think they call this a "natural sort"
ChrisDolan on 2006-12-13T18:27:24
Uh, of course, that's what I planned to write. That's my story and I'm sticking to it.Is i & 1 preferable to i % 1? I consider the latter to be slightly more intuitive.At least it gives the correct results.:-) Surely you ment to type $i % 2. :-P

{kind=link}